A Conceptual View
Before I outline the concepts of ERROS and its Connectionist Database, I think a little information about how I got into the area of Connectionist Databases and Artificial Intelligence may be helpful.
In many ways, it all comes down to luck, which, I learnt when working for IBM, could be defined as being in the right place at the right time.
My background originally was in investment banking and then stockbroking.
My first piece of luck in relation to Connectionist Databases was that my most recent computer course was a one week RPG course in 1965, during my training as an IBM /360 salesman. I have not been on any other course since then, not a System/38 or AS/400 or IBM i course nor even a database course. The disadvantages are obvious but, if you don't know how something is 'supposed' to be done it is probable that you will do it in a different, if not necessarily better, way.
I had a good run and a lot of fun at IBM, being involved, even in the 1960's, in major on-line financial systems, but was invited to run a computer bureau providing services in the investment area. I built up a team of about 40 staff, mostly developers, and it was here that I really learnt the practicalities of what a ridiculously complex process development was. I think I had a good team and we produced effective systems, but the costs were horrendous because of the inefficiency of the process. I later left the industry to run a group of about 45 companies, mainly in the Far East and West Africa, involved in manufacturing, service industries and import and export - "trading". The paper based systems (it was a long time ago) were totally inadequate and I had to get new, multi-currency systems in very quickly. Using knowledge from my financial background, I was able to do this, but it taught me how information systems that on the surface were apparently very different were in reality very similar. This was my second piece of luck, being most valuable when, later, I started to think about finding new ways of creating general purpose computer systems.
My (duplicate) concept of connectionism - I did not know then that the concept of connectionism had already been published by Dr. Vanevar Bush in 1945 - evolved when I was trying to design a system for cataloguing very large quantities of 17th and 18th century prints and engravings (by this time I was a fine art dealer). These are extremely complex objects, much more so than paintings (even though both might be described as 2 dimensional graphical objects). That this was my task was my third piece of luck. Relational databases were not then in the marketplace but they just could not have coped (and so still cannot). If I had known about them and that they were the leading edge of technology, I would not have had the temerity to try and create my own database. Innocence can be bliss! If I had been trying to catalogue paintings or create a normal commercial application, I would not have come up with the idea of the Connectionist Database.
One of the problems that I was able to anticipate was that, for reasons I don't need to explain here, constant, although simple, program changes would be required as we came across prints with cataloguing problems that we had not seen before. I was unhappy with this idea, and it suddenly occurred to me that this problem could be overcome by defining a small part of the application in the database. This is how the whole idea began. Once I had realised that you could define part of an application in a database, it was not a large step to realise that most of the application could be defined in a database. When I started to build the fine art system, my ultimate aim, whilst building this, was to create a new way of defining and creating general purpose commercial computer systems that would be dramatically simpler than existing methods. So the Connectionist Database was born. The name is based on the ability of the Connectionist Database to associate or relate data through myriad connections, in which capability it apparently has some similarity to the brain.
Let me emphasise again that I was not trying to create a truly intelligent database and, as yet, I have not done so. I believe that my concept is almost certainly a step in that direction, and one day I would like to investigate that further, but in the meantime I want to get the world using much simpler and quicker methods of building applications as this is a much more urgently needed solution than a truly intelligent database which might be considered as a solution looking for a problem.
The Connectionist Database that I have created is my implementation of my original concept. Someone else might license that same concept and produce a different implementation. I was concerned from the beginning with producing a solution with a practical use, one that would perform and be scalable. Since I would not be using or trying to build a machine with parallel processing capabilities, I did not attempt to clone the brain since I assumed the performance would be unacceptable.
The Connectionist Database in its present form cannot learn although it can be taught. I could in due course allow it to learn, using the same structure, but I do not believe that is what we always want for commercial solutions (although it would be nice in some areas). I have made compromises so that my implementation is not perhaps as "pure" as the concept. But these compromises have meant a much more practical result and far superior performance than otherwise might have been the case.
In a business, we do NOT want all users to have access to and to be able to update all information. If a database could learn and was totally accessible, then, when it learnt Fred's salary level, everyone else would know it and those colleagues that thought it too high would be putting up their own salaries (who would be able to stop them without some sort of filter?) so Fred would put up his own salary (and that of his boss, to ensure his own raise was approved!) etc.. The result would be anarchy.
To prevent this situation, I split application creation into two steps -
Building the business model
Creating applications that were filters to the parts of the business model relevant to the task.
The business model not only defines the data, but also provides an access path to it. The whole system is data driven. If I had not put in the second step of creating applications as filters, then any colleague looking up Fred's telephone extension would also see his salary. The information that anyone sees in Fred's record should be relevant not only to their seniority level but also to their task at that moment. It is all too easy to try and make computer screens look like old paper records and display every bit of information that we can fit on the screen about a person or thing so that the screens are constantly changing and are confusing to the user. IMHO, simpler screens means faster response times, greater ease of use and so greater productivity.
The NDB does not try to guess or create connections on the fly. It only does what it is told and it is the filters that control this. The filters of course are a part of the NDB - they are connections at a higher level.
So just what is a Connectionist Database?
Firstly, and most importantly, it is extremely SIMPLE, although, at first, it may not seem so.
When I started to consider how to construct my new database, I assumed that a small baby was not improving its powers of integration when learning to grasp an object for the first time and therefore it must be possible to model the complexity of the data of the real world without using advanced mathematics. Since I am not a mathematician, I had little choice! The only algorithms in the NDB are used for compressing identifiers and are based on mathematics that an 8 year old would understand. For those of you interested in compression algorithms, these do not create any duplicate addresses or waste any disk space as they do not work on direct addressing but simply on compressing the key field. The algorithms allowed me to use a fixed length key field even though the identifiers of the real world are variable and potentially of infinite length. Even if there are 1 billion² levels in a hierarchy (the maximum allowed in my implementation), the key field length remains unchanged (at 28 bytes in my implementation).
Artificial Neural Networks are based on maths, with complex algorithms, and are quite different to the NDB. They are concerned more with trying to learn, but not with large data volumes and cannot scale.
When thinking how to create an advanced database, I wondered how it was that human beings coped with the extraordinary complexity of the real world. It seems to me that, logically, the only way we can cope with complexity is by ignoring it! That is, we only consider a small part at a time - we do not try and retrieve every piece of knowledge about birds on a first "scan" - we just remember that "birds fly". If we think further, we may remember that there are breeds that cannot fly. Whilst thinking about birds, we are probably not worrying how to drive a car or the OVRPRTF command. The mechanism of the brain allows all these concepts to be integrated but it does not confuse us by insisting that we consider all our knowledge together, at one instant of time. The knowledge we gain on any one subject tends to come in small drops over a long period of time, rather than as a flood. We cannot anticipate how much knowledge of any subject we may acquire nor whether, or to what extent, any new knowledge may fit in with, modify or contradict our knowledge on the same or other subjects. Traditional databases tend to work with fixed length records.
At this stage, do not worry about how an NDB might be implemented - just consider it conceptually. In essence, it is a database in which all "things" are defined by direct connections with other "things", and indirectly through other more remote connections. There can be "types of things" ("classes" in OO terminology and "entity types" in my Connectionist Database technology). Things (i.e. entities) can belong to many "entity types" and they can inherit the properties ("attributes") of the "entity type" under which they are being considered.
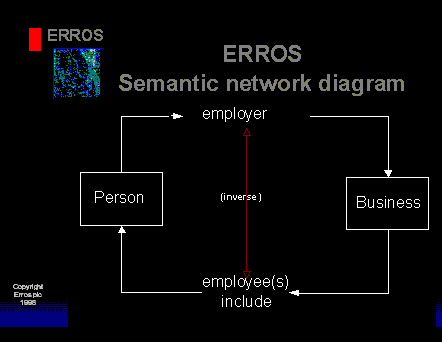
Let me try and explain. If Fred Smith works for the ABC Company, he is their "employee" but they are his "employer". In other words, "employer" and "employee" are the inverse of each other and describe the same relationship from different viewpoints. "Employer" is an attribute of the entity type "people" whilst "employee(s)" is an attribute of the entity type "company".
People like diagrams so please look at the diagram below -
"Person" is an entity type that has an attribute "employer" that is a relationship with another entity type "business". That in turn has an attribute "employee(s) include" that is the inverse of "employer" and is a relationship with the entity type "person".
Note 1: This diagram restricts people to being employed by businesses alone. To allow the concept of people also being employers we would have to create a second diagram with "person" as the entity type on both sides. However, we would not have to redefine the attribute "employer" for "person", and, as "employee(s) include" has already been defined as an attribute (of Business), we simply have to define it as also being an attribute of "person".
Note 2: We only generally need to consider each diagram individually. The NDB automatically provides the integration. We can undertake incremental development and we do not have to have full up front knowledge or write a specification.
Note 3: Since the NDB provides the integration and we do not ever have to consider or understand the "whole", we can add new attributes to existing entity types at any time, without first having to consider the implications of so doing on existing applications. Unless we add to the filters that make up an application, the application will not "know" that the extra attribute has been added and will remain unchanged.
The Semantic Network Diagram is like the Entity/Attribute model but with the vital addition that the attribute is not the same for both entity types. Thus all relationships are bi-directional - if we know the name of a company we can look up a list of its employees or if we know the name of a person, then we can look up the name of their employer. Bi-directional relationships allow us to navigate the database in either direction at the same speed. So if we look up Fred Smith and find the ABC company is his employer, we can immediately move from the record for Fred to that for the ABC company and then look up information about the ABC Company, such as their address, or the list of all employees recorded in our system, or whether they are a supplier or a customer or perhaps a prospect of our company, or all three. If they are a supplier, we could then look up the list of orders that we have placed with them, or, if they are a customer, the list of orders that they have placed with us. If they have placed an order for a particular product, we could then look up all orders or manufacturing schedules for that product, etc..
There can be many other relationships between Fred Smith and the ABC Company, such as job title, job description, salary, orders that, as a salesman, he takes on behalf of his employers. etc.. It is important to understand that these additional relationships only exist because of the prime relationship (employer - employee) between Fred and the ABC Company - if Fred left the ABC Company they would cease although their history should remain. The additional relationships are therefore at a lower level - they are relationships with relationships. This can be modelled by the Connectionist Database without problem.
The address of a person or company is stored, not as a text type field in a contact record, but as a relationship with a particular address (an entity) in an entity type called "Addresses". If a company only has one address, this is stored only once even if they are both a supplier and a customer, so that there is no redundant information. Thus if we access a particular customer record and enter their address, if they are also a supplier and we look up their address, we will find the address that we have just entered. If multiple subsidiary companies of the same group trade from the same address, then they all have a relationship with the one address. Looking up that address, we can find all companies that trade from it and, for each company, a list of their employees, etc.. If one of the companies alone moves to a new address, then we create a record for the new address, mark the relationship between the company that is moving and the old address as deleted (not an OS/400 delete which is really a remove) and create a relationship between the company that has moved and the new address. The tag for deletion facility allows history to be kept. We can further refine this by allowing date/time stamps to be used to define when a relationship started and ended so that we can find out in which sequence and for how long they were at each address. We do not need a field called "current address" and another called "previous address". Attribute definitions allow multiple iterations by default, allowing repeating fields and repeating groups of fields, although the number can be restricted when required. The NDB automatically handles history in a way not possible with RDBMS's.
Jane Brown might also be an employee of the ABC Company. In this case there is an indirect relationship between her and Fred Smith, through their employer. As we add more employees for the ABC Company, we do not keep needing to add their employer's address for each employee as we have already defined it as a relationship with the ABC Company.
In a Connectionist Database, there is no obvious beginning or end to the database - that is just a matter of perception. In the simple example above, you can start with a person or with a company or an address or a product or an order and stop when you have learnt what you require, limited only by your security and the filters provided in the applications to which you are authorised.
The concept allows the use of any language whose character set can be entered using your keyboard. Although I have not tried it, it should be easy to get it working with DBCS languages. Like the brain, the NDB is language independent and has no preferred "natural" language, only what it is taught. There are no reserved words and businesses can use their own business terminology, without any restriction. If one business has "clients" and another has "customers", that is not a problem. If a company uses both terms, then a standard "synonym" facility of the NDB would allow one of the terms to be used as the standard and the other as a synonym that leads to the first.
But how are the definitions about people, companies, addresses, etc. defined?
By exactly the same process, using relationships or connections. At this point, it may become a little confusing, but persevere and you should easily understand it. Remember, it is simple.
Consider the term "entity type" which might be loosely defined as a collection of "things" that have similar characteristics and that may be conveniently grouped together and about which we wish to store information. If you think about it, "entity type" is, itself, an "entity type".
Attributes are a collection of "properties" or characteristics so we may consider "attribute" as another "entity type". The relationship between "entity type" and "attribute" is defined in the following diagram -
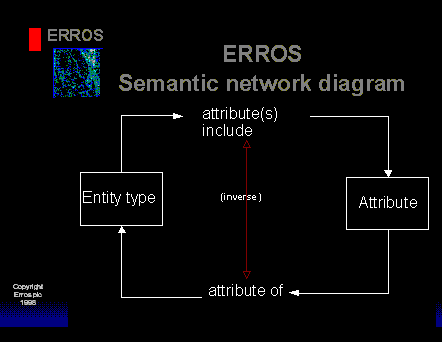
One attribute might be "address". This might be an attribute of a variety of entity types, such as
At this point, no addresses have been entered, so no space for storing addresses has yet been taken. We can now start entering addresses for any Agent, Business, etc. where we know them. We can do this even if the complete application has yet to be defined. If addresses are a new concept and the business only has addresses for, say, 5% of customers, then, when these are entered, only 5% of customer records will have space used for an address. We do not have to put in "null" values for the remaining 95% of records. If the attribute address is defined as allowing multiple iterations, then, when any agent, business, etc., has more than one address, the system will cope without problem. We could change the number of address iterations allowed for each entity type of which address is an attribute.
Attributes may be defined as non-relational, containing independent data, such as height or text, or as relationships.
If we define address as an independent attribute, then to find the person or business at a particular address, we would have to search all records and look at their addresses, a slow process in a large contact database. If however, we define the attribute as a relationship, we can go straight to the entity type "address", retrieve the address by name (state first, town, etc.) or by Zip or post code and then immediately find the relevant people etc. at the address. This would only take about 1 second even in a very large contact database on the slowest AS/400 (B10).
Entity types like Agent, Business, etc., are not the only ones with the attribute "address". We can consider all business processes, forms, etc. as further entity types. So the entity type "Sales Invoice" would also have the attribute "address", as well as "customer name", "customer number", "invoice date", etc.. Customer name would be defined as a relationship with the entity type "customer", the customer being identified by name and/or number. "Address" also be defined as a relationship with the entity type "customer", but with the "address" of the customer already selected as the customer in the invoice, so that, once we have identified the customer for the invoice (probably from a sales order), the application will automatically retrieve the correct address.
Since all relationships in the NDB are bi-directional, we can, if we have authority, look up the attribute "address" and find out all those entity types, including business processes (manufacturing, deliveries) and forms (sales orders, invoices, etc.) to which they belong.
The concept of fixed length records of traditional databases has gone. Whilst the user will perceive a "logical" record containing all the data that is available to him about a particular entity, he will not be aware how it is stored nor that there is other data about the same entity available in the same application but with higher level security or in other applications to which he is not authorised. The maximum amount of data in a single "logical" record is very large - over 130 X 1 billion² bytes in my implementation. In practical terms, that means that there is always space to add new data to any record, yet there is no overhead if the space is not used.
There is no real difference between meta data or user data. The NDB handles them in the same way. The application "filters" ensure that only those who are authorised can change the meta data, and the ordinary user will not, as a rule, be authorised even to look at all meta data. There may be a very large number of attributes defined for a particular entity type, yet there may not be one application that provides access to them all.
Once an attribute, such as "name", has been defined, it can be re-used as much as is required. Creating new entity types which also have the attribute "name" requires no new programming, no new display file formats and no new physical or logical records as it is just more data in our existing database. If this already has back up procedures and journalling in place, then we do not need to consider these issues for any new entity types.
Since we are just adding extra data to our existing database, and are
not creating new files, and do not know or need to know where the data
in the attributes is stored, then we are no longer concerned with physical
file design. All data is automatically stored in its context and
we can only retrieve it in context. This determines where and how
data is to be stored but we do not need to be concerned with how that mechanism
works.
The Application "Filters"
An application is just another entity type.
5 important attributes for the entity type "application" are -
The lower level contains attributes that are at a lower level e.g. "job title" after we have selected
There can be up to 999,999,997 further lower level menus in my implementation, each one at a lower level than the one before. I haven't yet worked out how to use them but if I had chosen say 100 which still seems way too many, I might have eventually found a limitation and regretted it. Once again, there is no overhead in allowing so many levels.
All of these attributes for "Application" would be defined as relationships, and all can be defined using the semantic network diagram. The following diagram is for defining the relationship between Applications and entity types.
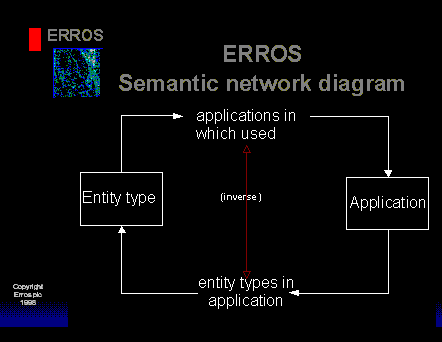
Thus the NDB provides its own application development environment.
The concept of a development tool, external to the database as with traditional
systems has gone.
The last diagram above and the others could have been drawn the other way round, e.g. last the one above with Application on the left and Entity Type on the right and with the position of the attributes reversed. You by now should be getting the basic concept that all data and meta data is the same and that we can use a universal data type throughout.
One diagram can be used that covers both user data and meta data.
You just choose the appropriate entity type and attribute names to suit your situation. If you were doing development using the NDB on a regular basis, then you would probably not bother to draw any diagrams, but just type in the definitions. All authorised developers can check definitions, and since they are created using the terminology and natural language of the business, they can easily understand their own work and that of their colleagues. Basically, the NDB is self documenting.
I believe that the Semantic Network Diagram can be used to model most, and perhaps all, ordinary "back office" business data. I have not had any problems and I believe that it truly can model the complexity of the data of the real world.
This is of course a conceptual document and I have not tried to cover all eventualities here. In any event, it is much easier to understand the concept by trying it than reading long papers about it.
The main problem in creating a Connectionist database is that it defined by itself and you cannot create it until you have created it! Obviously you can overcome this problem - I have done so - but it is not a five minute exercise.
Controlling Terminology
If you go to create a new entity type and it is already there, the Connectionist Database will tell you, but it would be improved by having a thesaurus or repository in which all terms are stored. This is simply another entity type. The following diagram shows how this would fit -
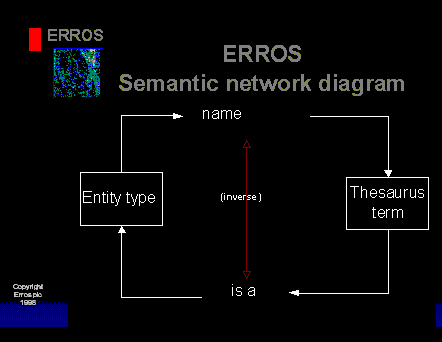
The attribute "name" of the entity type "entity type" is now defined as a relationship with the Entity Type "Thesaurus Term". This means that when we create a new entity type, the term must already exist as a Thesaurus Term. Once the new entity type has been created, if we look up the term in the entity type "Thesaurus Term" and access the attribute "is a", we will find that the term is an "entity type". If we select this record, we can now see the properties of the entity type. The same technique would be used for defining attributes - these would also be a relationship with the entity type "Thesaurus term".
In any business, we need a variety of standard terms which, for instance, we may use to classify other records. As an example, we may like to view companies by their "type of business". We can use the following diagram to create the standard list of types of business.
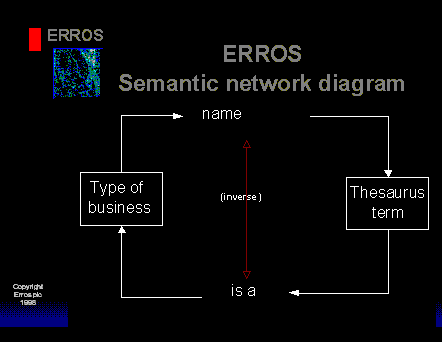
You might consider that "type of business" is an hierarchy. With the semantic network, you can find out to which hierarchies any term belongs by accessing it in an entity type such as Thesaurus term and then looking up the attribute "is a". You do not have to search each hierarchy to find the hierarchies to which the term belongs.
The following diagram would be used to allow the use of the terms "type of business" to classify each business-
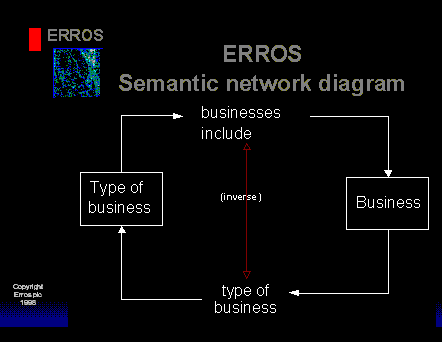
The document contains above samples of semantic network diagrams to illustrate how you build simple applications, although the examples would be clearer with screen dumps. You may wonder at this point "What about processing?".
The Connectionist Database is not like a database server which stores and retrieves data as instructed by external programs which are coded to provide a particular function. A small set of kernel programs (in my implementation under 50,000 lines of RPG) provide all the functionality required for database update and retrieval, journallling and commitment control, for handling record identifiers (e.g. name or date/time or reference number or code) and for providing the 5250 and HTML screen output and HP PCL printer output. For applications in which attributes only consist of one field or have multiple attributes from a list of predefined attributes with multiple fields (such as "name and/or number), nothing else is required, even where the database structure is of considerable complexity. The Connectionist Database with its simple kernel programs is totally self contained - it is simplicity itself. Because the same kernel programs are used for both the development and the operational environments, all users are using the same code, whatever the application. Because the code is so small (about 4.5Mb in total), it will be held just once in the main memory of an AS/400 without any paging, however many users there are. This has obvious performance benefits and frees up the disk arms for their true purpose, storing and retrieving user data. Once an operator has started a task, called his ERROS kernel programs and opened the ERROS files (10 in my implementation), the programs remain called and the files open until the task is ended, even though the operator may change applications within that task.
Rob Dixon